0427 Method Course Presentation
AI in government-citizen communication
From interaction quality to deployment infrastructure
Paper 1
AI language modification and communication quality in government-citizen interaction.
Paper 2
PEARL and label-efficient representation learning for retrieval-based systems.
Today I will introduce two connected papers. The first is a public administration paper about whether AI language modification improves communication quality between government and citizens. The second is a method paper that moves one layer deeper. If we want to deploy AI in these communication systems, we also need reliable retrieval and classification infrastructure when labels are scarce.
Paper 1
Communication quality is not only information transfer
Citizen message
->
AI modification
->
Government response
Potential benefit
- clearer information
- more polite tone
- lower response burden
Core concern
- standardized language
- muted emotion
- weaker urgency signals
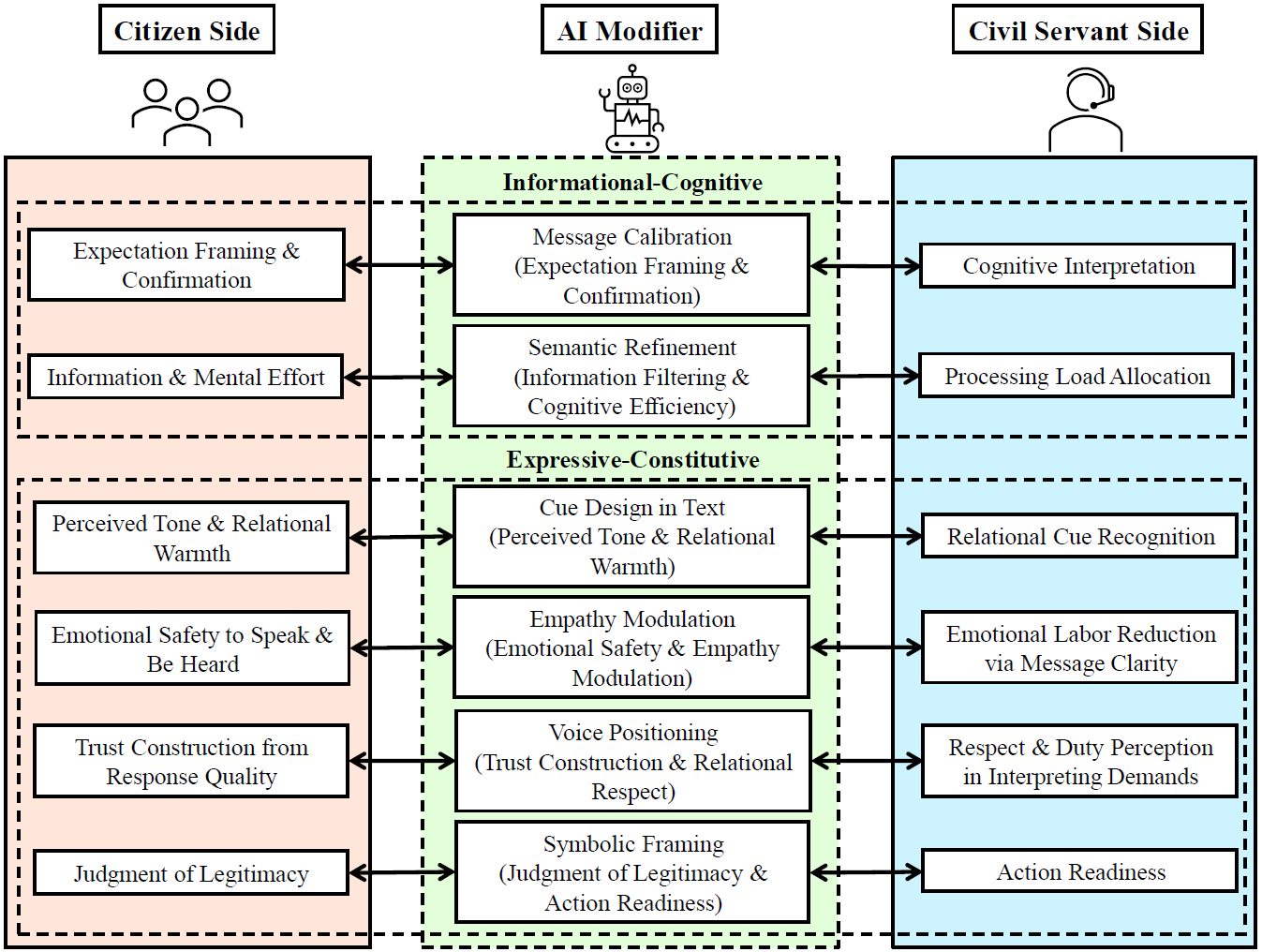
The first paper starts from a practical observation. Government-citizen interaction is increasingly text-based. Citizens write online messages, and officials reply through platforms. AI can make this communication clearer and more polite. But communication quality is not only clarity. It also includes respect, empathy, feeling heard, trust, urgency, and emotional signals. So the key question is whether AI improves communication in a deeper way, or whether it only makes the message look polished.
Framework
Two sides, two layers of communication quality
Informational-cognitive
clarity, satisfaction, ease of reply
Expressive-constitutive
politeness, respect, feeling heard, empathy, trust, urgency
The framework separates two kinds of communication quality. The first is informational-cognitive: does the message become easier to understand and easier to respond to? Here the expected effect of AI is quite direct. The second is expressive-constitutive: does the message express respect, emotion, responsiveness, and legitimacy? This is more contested. AI may improve surface politeness, but it may also reduce emotional signals that tell officials a case is urgent or needs empathy.
Research design
Vignette-based survey in China
Participants
220 citizens
214 civil servants
Contexts
requests, inquiries, complaints, suggestions, emergencies
Comparison
original messages vs AI-modified messages
Analysis: paired t-tests and mixed-effects regressions.
The design uses real-world government-citizen communication scenarios from China. The survey includes citizens and civil servants. Citizens evaluated government responses, while civil servants evaluated citizen messages. Each participant saw both original and AI-modified versions across different topics. This within-subject structure is useful because each participant partly serves as their own control. The analysis combines paired t-tests with mixed-effects regressions.
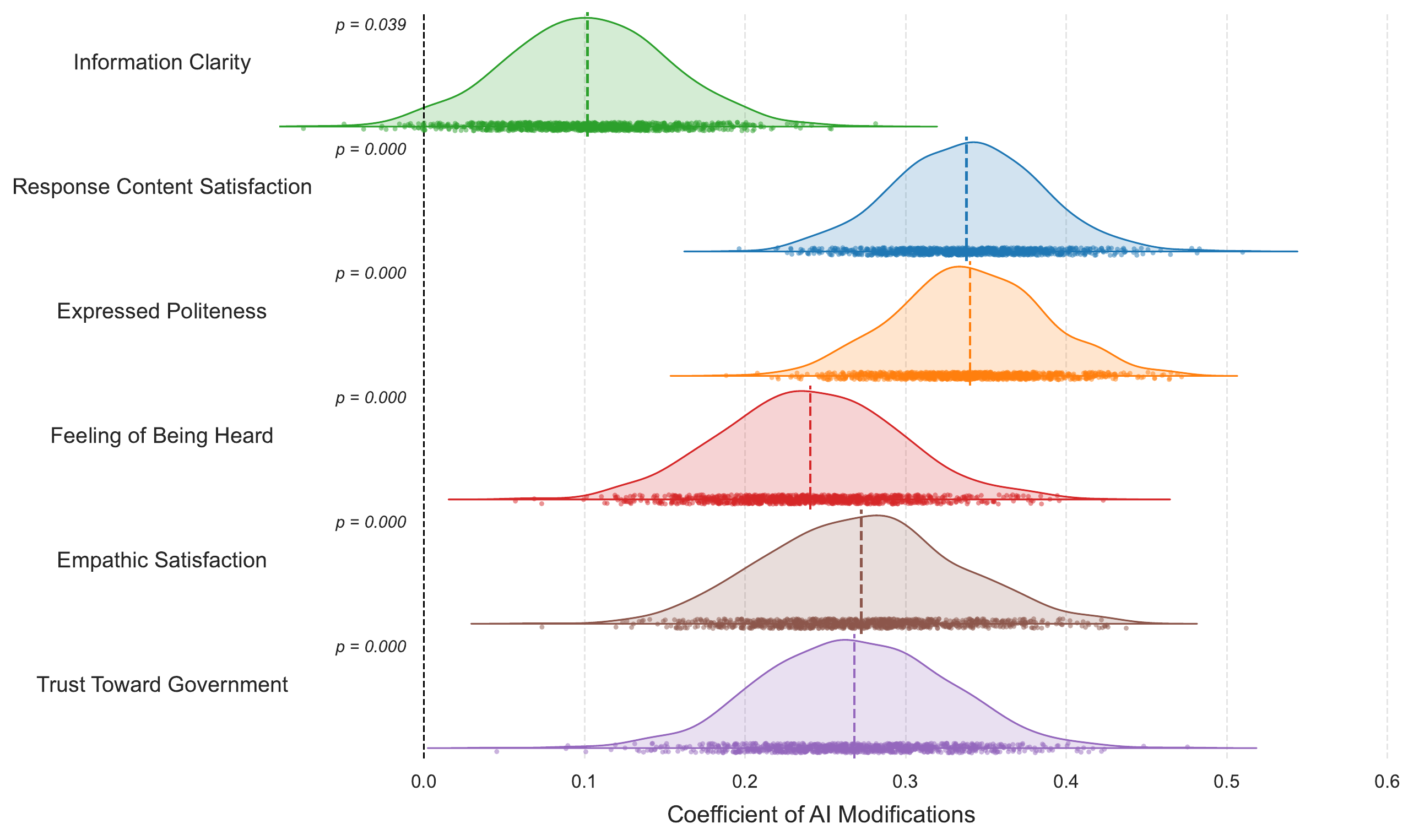
Citizen-side findings
AI improves citizen perceptions across all six dimensions
- information clarity
- response satisfaction
- expressed politeness
- feeling heard
- empathic satisfaction
- trust toward government
The findings are clear on the citizen side. AI-modified government responses were rated higher across all six dimensions, including not only clarity and satisfaction but also feeling heard, empathy, and trust. The important point is that the improvement is not only instrumental. It also appears in relational perceptions. This supports the idea that AI language modification can improve both the informational and relational sides of public communication.
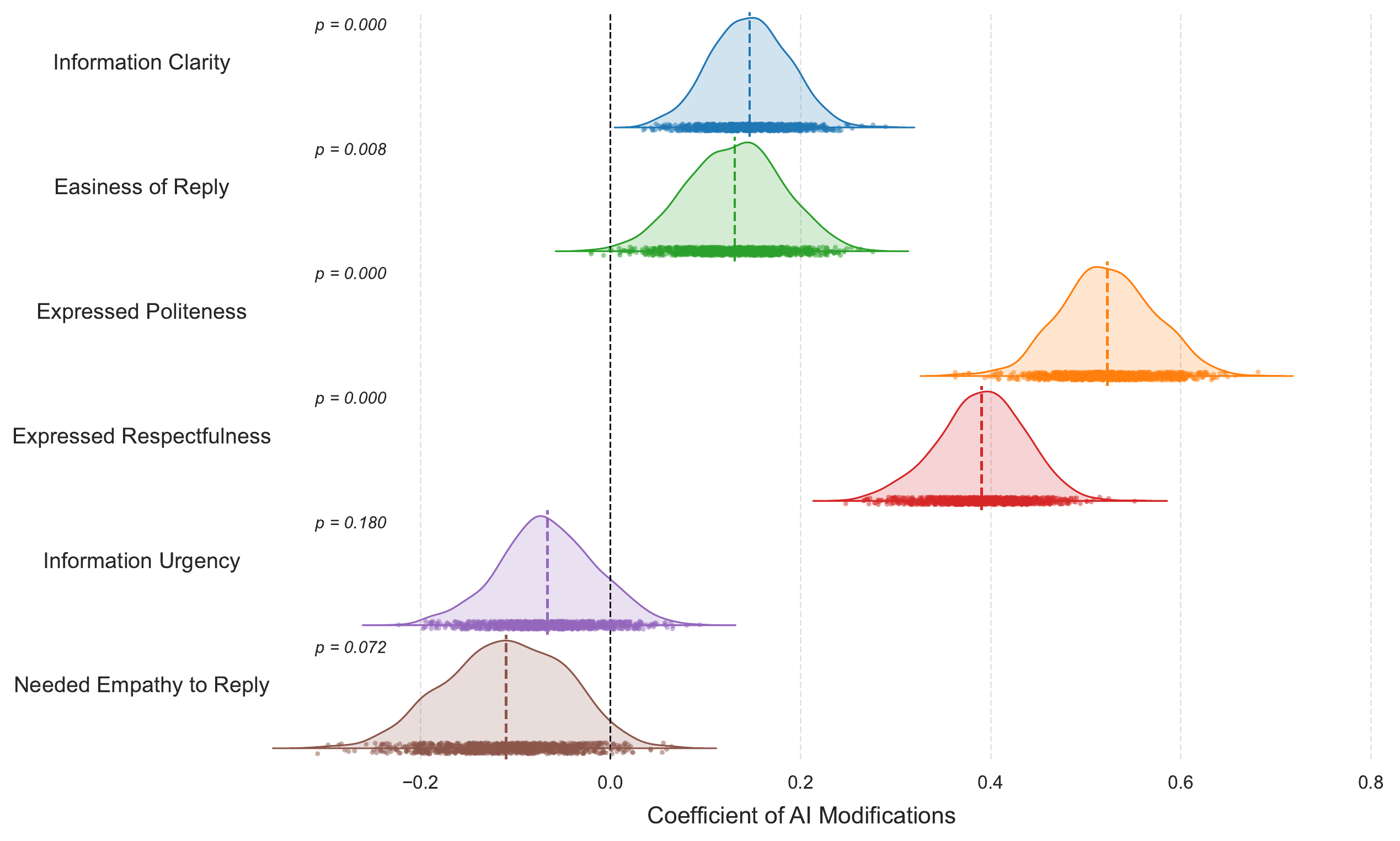
Civil servant-side findings
AI reduces friction without clearly erasing urgency
- clarity increased
- easiness of reply increased
- politeness increased
- respectfulness increased
- urgency and needed empathy were not significantly reduced
On the civil servant side, AI-modified citizen messages were clearer, easier to reply to, more polite, and more respectful. Importantly, the paper does not find consistent evidence that AI significantly reduces urgency or needed empathy. This means the strongest version of the emotional-flattening concern is not supported here, although the paper still treats it as a context-dependent risk.
Bridge to Paper 2
Better wording is only the front-end layer
Interaction level
clarity, politeness, empathy, trust, burden
System level
routing, retrieval, category matching, similar cases
If nearest neighbors in embedding space are wrong, the system retrieves the wrong cases.
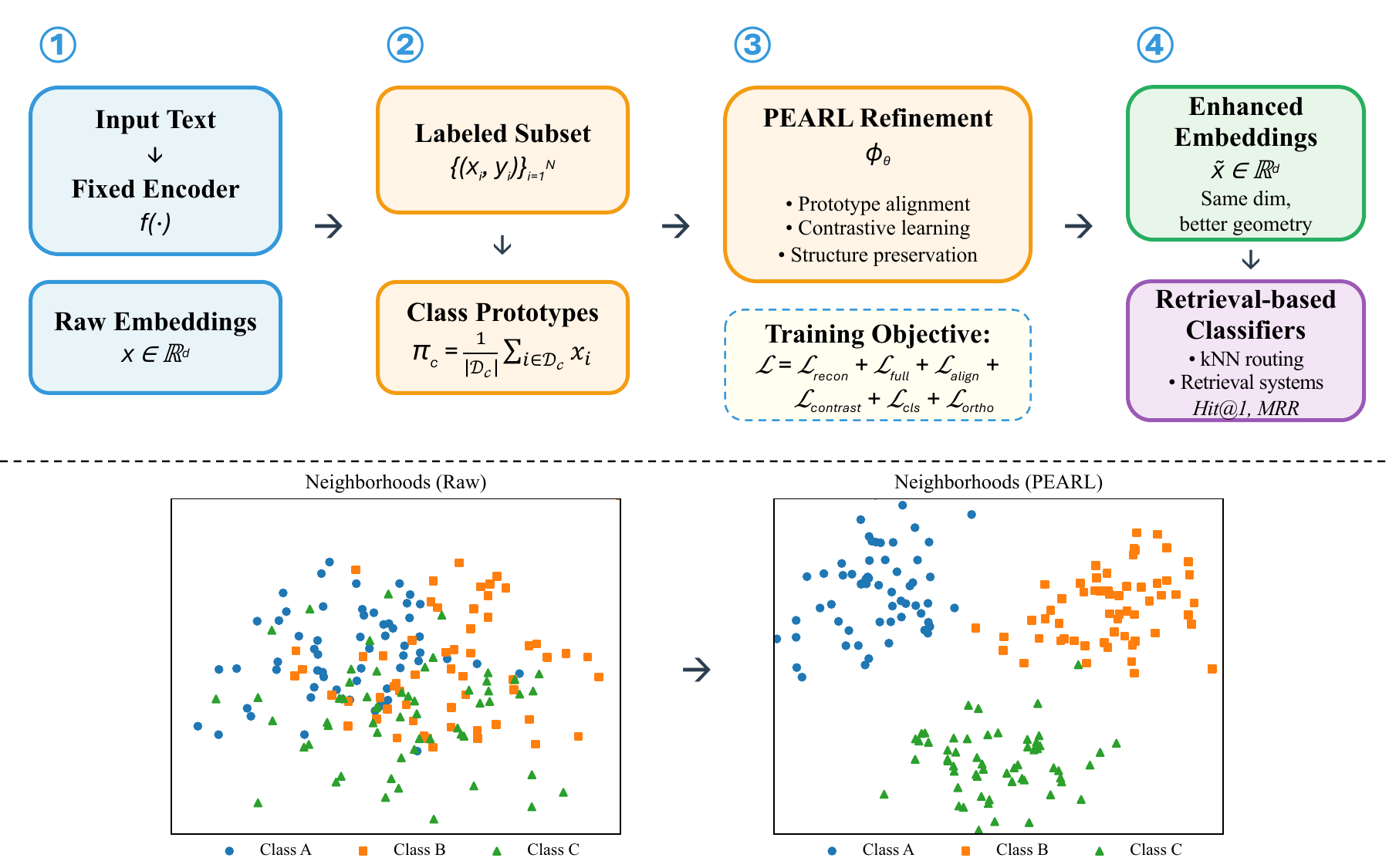
This is where the second paper enters. Once we imagine AI-assisted communication in real systems, the task is not only rewriting a message. The system also needs to retrieve similar cases, route messages, and suggest relevant categories or policies. These tasks often depend on embeddings. If the nearest neighbors in embedding space are wrong, the system retrieves the wrong examples. So the method question becomes: can we improve embedding geometry with only limited labels?
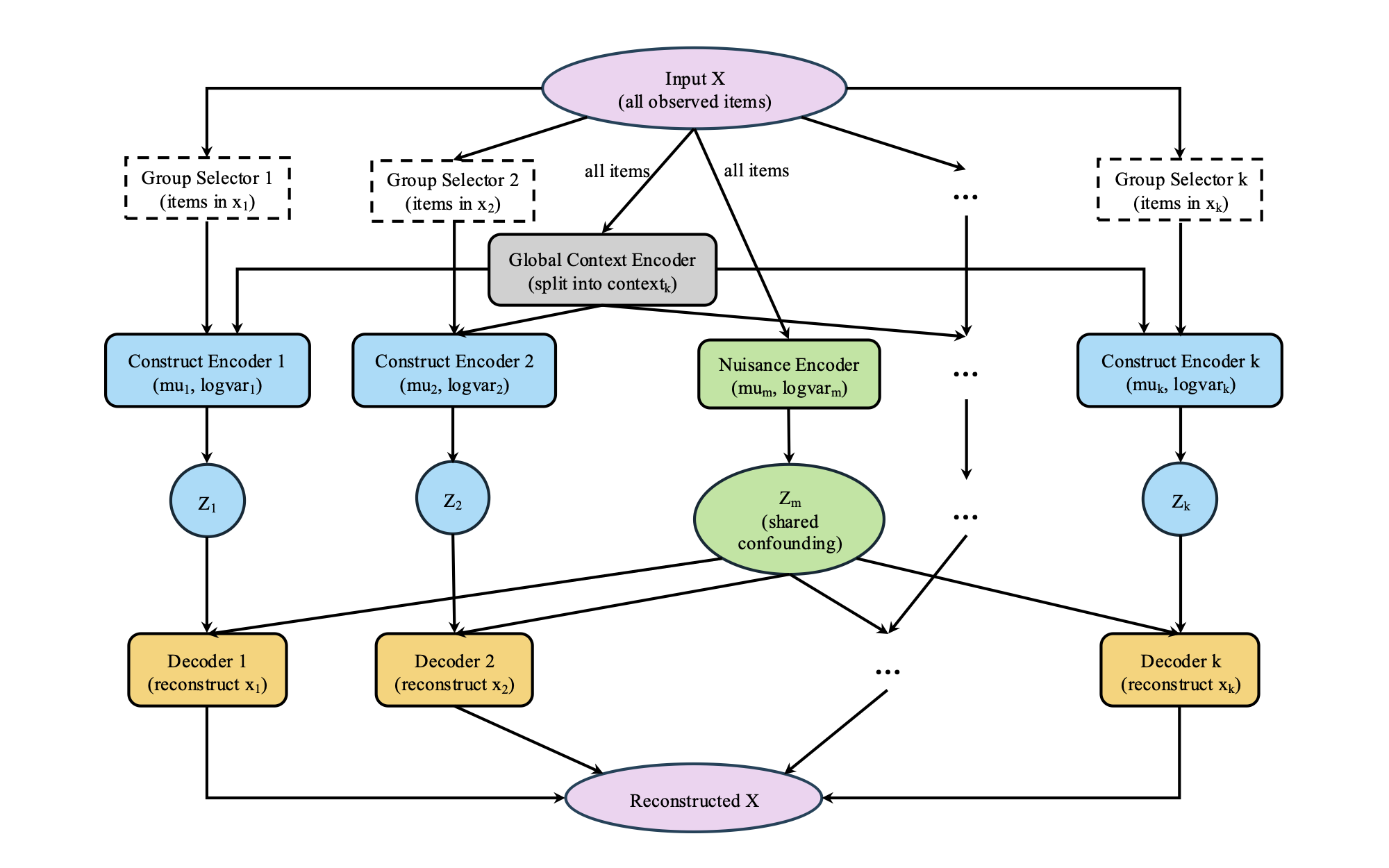
Previous work: SE-VAE
Technical foundation: structured embedding representation
Latent structurelearn compact representations
Semantic alignmentconnect text space and task labels
PEARL extensionreshape fixed embeddings for retrieval
Before PEARL, my earlier SE-VAE work already focused on representation structure. The key connection is that PEARL inherits this concern with embedding geometry, but turns it into a lighter post-processing approach for fixed embeddings and retrieval systems.
Paper 2: PEARL
Label-efficient geometry shaping for fixed embeddings
zi=f(xi), yi ∈ {1, ..., C}
pc=1|Lc| ∑i ∈ Lc zi
sic=cos(zi, pc)τ
P(c|i)=exp(sic)∑k=1C exp(sik)
L=CE(yi, P) + λ ||z'i - zi||22
z'i=norm(zi + αWzi)
ziembedding vector for one text
pcaverage vector for class c
sicsimilarity score to prototype
P(c|i)probability text belongs to class
Ltraining loss: fit label, avoid distortion
z'irefined vector used for retrieval
Inputfrozen embeddings
Anchorclass prototypes
Outputretrieval geometry
PEARL targets a practical problem. Many systems already use fixed embeddings from large pretrained models. But these embeddings are not always organized in the way a deployment needs. PEARL uses limited labels to form class prototypes, then gently reshapes the embedding space so local neighborhoods become more label-consistent. The point is not to train a new foundation model. It is a lightweight post-processing step for systems where retraining is expensive or impossible.
Results and deployment meaning
PEARL improves early retrieval when labels are scarce
| Evidence point |
Raw / baseline |
PEARL |
Gain |
| Overall low-label neighborhood quality |
Raw embeddings |
Prototype-aligned embeddings |
+25.7% over raw |
| Against unsupervised post-processing |
Centering / L2 / whitening-style fixes |
Uses limited labels as anchors |
+21.1%+ over strong unsupervised baselines |
| Purity@1, 300 labels |
0.3824 |
0.5370 |
+0.1546 points; about +40.4% |
| Hit@1, 600 labels |
0.4386 |
0.6054 |
+0.1668 points; about +38.0% |
| MRR@20, 1200 labels |
0.6202 |
0.7186 |
+0.0984 points; about +15.9% |
| Purity@5, 2500 labels |
0.4540 |
0.6359 |
+0.1819 points; about +40.1% |
The main result is that PEARL is strongest in the regime many public-sector deployments actually face: limited labels, fixed embeddings, and reliance on retrieval. It improves local neighborhood quality and early retrieval, especially Hit@1 and MRR. This matters because civil servants often inspect only the first few retrieved cases. When more labels become available, fully supervised methods can become stronger, so PEARL is not claiming to dominate every setting. Its value is as a practical, label-efficient geometry correction.
Closing
One research agenda: evaluate AI at two levels
Interaction level
- clarity
- politeness
- empathy and trust
- frontline burden
System level
- retrieval quality
- label efficiency
- drift monitoring
- auditability
Good AI governance communication is not only better wording. It also requires systems that retrieve the right cases and adapt with limited supervision.
Together, the two papers form one research agenda. The first paper evaluates what AI changes in the communication experience. The second paper asks how to support that communication system technically when labels are scarce and the environment changes. My final takeaway is that AI in public communication should be judged at both levels: the interaction level and the system level.